Металлоискатель для „минерализованной почвы“ рынка закупок
Предисловие автора
Сегодня «Госбаза» — это больше чем сервис. Это интеллектуальный инструмент, который в реальном времени прогнозирует участников и победителей торгов по всем федеральным законам, включая сферу коммерческих закупок. Более тысячи специалистов одновременно используют её модели в своей ежедневной работе.
Я помню ваши слова о том, как вы любите читать мои развёрнутые письма о нововведениях. Ценю это доверие. Что ж, ловите — специально для вас я снова сел за печатную машинку.
Когда-то мои длинные письма стали для кого-то привычкой, для кого-то — источником идей, а для кого-то — просто оправданием, чтобы выпить лишнюю чашку кофе. Вы просили продолжить — я не мог вас подвести. Устраивайтесь поудобнее — как в старые добрые времена, я снова рассказываю о самом важном, что у нас произошло, делюсь идеями, отчётами о проделанной работе и планами на будущее.
Это письмо — рекордсмен. Самое длинное за всю историю, которые я писал и как обычно в моем случае, нарушает все известные нормы email-маркетинга. Но внутри есть то, ради чего стоит прочитать каждое слово. Обещаю!
В нём нет кричащих кнопок «КУПИТЬ СЕЙЧАС СО СКИДКОЙ 300%». Почему? Потому что мы верим, что лучшая реклама — это не громкие обещания, а понятная ценность.
В мире, где нас постоянно торопят совершить импульсную покупку, мы выбираем другой путь. Мы не продаём вам доступ к базе — мы предлагаем партнёрство в решении сложной задачи. А для этого нужно сначала разобраться, как именно эта задача решается.
Это письмо — и есть наша главная «реклама». Это подробная инструкция, технический брифинг и открытый диалог в одном флаконе. Если после его прочтения вы захотите попробовать — отлично. Если решите, что ваш текущий инструмент справляется — мы будем рады, что помогли вам это понять. Наша цель — не «впарить», а помочь принять осознанное решение.
Мы настолько уверены в качестве нашего продукта, что можем позволить себе подробно, без прикрас, объяснять, как он работает. Наша лучшая реклама — это ваше понимание и ваше доверие, заработанное честным путём.
Пристегните ремни!
Если мы ещё не знакомы — самое время это исправить
Меня зовут Максим. Для одних я — разработчик, для других — автор, а для самого себя я, пожалуй, — первопроходец. С 2009 года я в одиночку, шаг за шагом, строил “Госбазу”. Не по чертежам, а по наитию. Не из амбиций, а из желания решить одну единственную, но огромную задачу — сделать невидимое видимым, а сложное — простым.
Это не просто «ресурс». Это мой ребёнок. Тот, который не спал по ночам, капризничал, требовал бесконечного внимания, но и радовал каждым своим новым умением. Я учил его — а он учил меня. Мы росли вместе.
И теперь я с гордостью и лёгким трепетом знакомлю его с вами. Не как с бездушным инструментом, а как с верным помощником, в которого вложена частица моего мира.
В 2009 году это был всего лишь код на экране и идея в голове. Сегодня — это живой организм, который дышит данными, говорит прогнозами и мыслит алгоритмами.
Я создавал его один. Каждую строку кода, каждую логическую связку, каждый интерфейсный элемент. Это был путь не стартапа с инвесторами, а ремесленника в своей мастерской. Со своими прорывами, ошибками, ночами у монитора и моментами, когда казалось, что всё летит в тартарары.
Но именно поэтому я знаю о Госбазе всё. Я чувствую её не как программу, а как продолжение собственного мышления. И сегодня я готов делиться этим мышлением с вами.
В 2009 году я решил изменить правила игры в госзакупках. В одиночку.
С тех пор я — автор, разработчик, тестировщик, техподдержка и, конечно же, главный фанат “Госбазы”. Я не просто создал сервис. Я вырастил идею: что работа с данными может быть не рутиной, а творчеством. Не игрой в угадайку, а точным прогнозом.
И теперь я смотрю на то, во что она выросла, и понимаю — самый важный код, который я написал, это не код базы данных. Это код доверия между мной и вами.
За каждым прогнозом стоит не просто алгоритм — стоит моё убеждение, что любая, даже самая сложная система, может быть понятной и дружелюбной.
Поэтому это письмо — не просто анонс новых функций. Это искренний рассказ о том, как мы растем вместе с вами. О том, какие задачи учимся решать и какие горизонты открываем.
И помните: за каждой строчкой тут стою я — Максим, который всегда на связи и всегда открыт для вас.
Это письмо родилось из диалогов, вопросов и вашего доверия. Тем не менее, у него есть три ключевые задачи.
Во-первых, я хочу приоткрыть дверь в техническую лабораторию «Госбазы» — чтобы вы не просто использовали прогнозы, но и понимали, как они рождаются. Знание процессов «под капотом» даёт уверенность и качественно новый уровень работы.
Во-вторых, рассказать о новой модели принятия решений в условиях многомерной и изменчивой среды. Это ваш новый компас, который поможет находить оптимальные пути коммуникации с клиентом даже в море альтернатив.
И наконец, это информационное руководство создано для того, чтобы стать вашим ежедневным помощником. Здесь собраны ответы на большинство вопросов, которые возникают в практике работы с системой. Пусть оно сэкономит ваше время и усилит результат.
Рад, что мы продолжаем этот путь вместе.
Быть первым — устаревшая концепция. Быть эффективным — новая реальность
Друзья, наша главная цель — добиться того, чтобы фраза «Я первый увидел протокол!» вызывала не восторг, а лёгкое недоумение: «Серьёзно? Ты всё ещё этим хвастаешь?».
Хватит бежать за протоколами с секундомером. Мы движемся к миру, где скорость важна не для того, чтобы просто быть первым, а для того, чтобы первым предложить решение.
Мир изменился. Первый увидел протокол — получил стресс. Второй увидел протокол — получил клиента. Выбирайте, что важнее.
Представьте: вы звоните клиенту и с пафосом, как супергерой, объявляете: «Вы победили в аукционе!». А в ответ —
«Спасибо, Капитан Очевидность! Я уже успел отметить и в отпуск улететь. Вы кто такой вообще?»
Он уже час как празднует, успел всё обсудить с бухгалтером, юристом и собственной собакой, а вы ему — как тот гость на празднике, который принёс салат, когда все уже торт едят. Фраза «вы победили» — это как поздравлять с Новым годом первого января в семь вечера. Все уже в будущем, а вы всё ещё в прошлом.
Но что, если сменить пластинку?
Вместо того чтобы сообщать ему то, что он УЖЕ знает, вы приходите и говорите:
«Слушайте, а вы не хотите работать с нами на постоянной основе? Мы заметили, что вы стабильно выигрываете тендеры у администрации Солнечного Города на поставку марсианских огурцов. У нас в pipeline’е > ещё пять таких же аукционов — давайте мы будем заранее присылать вам аналитику, чтобы вы могли подготовиться, рассчитать закупки и занять все пьедесталы до того, как конкуренты опомнятся».
Вы превращаетесь из «последнего, кто узнаёт новости» — в того, кто эти новости создаёт. Из почтальона Печкина — в генератора рыночных инсайтов.
Это уже не «Клиент, вы победили!», а «Клиент, давайте мы сделаем так, чтобы вы побеждали там, где даже не планировали». Как говаривал мой дедушка в 80-х, «это уже совсем другой коленкор». И да, он носил кепку и говорил мудрые вещи. Доверяйте дедушкам и правильным данным.
Поиск клиента — как выслеживание реликвий с помощью металлоискателя
Представьте себя на пороге бескрайнего поля, где под слоем земли скрыты вековые реликвии. С металлоискателем в руках вы полны надежд и уверены: «Здесь точно есть сокровища!». Впереди трактор, которым управляет ваш тесть, вспахивает землю. Вы следуете за ним, сканируя почву, но… прибор молчит.
Первая мысль — поле уже опустошено другими искателями. В голове рождаются оправдания: «Всё уже нашли до меня! Все ценные клиенты разобраны, все пятаки Екатерины и царское серебро давно в чужих руках». И кажется, что проще всего опустить руки и двинуться на другое поле.
Но стоит сменить локацию — история повторяется. Возникает соблазн списать всё на инструмент: «Вот куплю детектор новой модели, подороже — и сразу найду всё!». А к вечеру, уставший и разочарованный, с парой ржавых гвоздей и царским медяком в кармане, ты уходишь с поля, злясь на себя и на удачу.
Однако настоящий кладоискатель знает: проблема редко в поле или в приборе. Она — в стратегии. В умении читать ландшафт, анализировать условия, настраивать оборудование и действовать не вопреки, а благодаря обстоятельствам.
Так и в поиске клиентов: недостаточно просто иметь доступ к базе данных или самый дорогой софт. Нужно уметь видеть скрытые связи, понимать логику рынка и делать точные «раскопки» там, где другие прошли мимо. Удача улыбается не тому, кто быстрее бежит, а тому, кто знает, куда и зачем бежать.
И иногда — достаточно просто поднять взгляд, чтобы заметить тропу, которой шли другие. Тропу, ведущую к сокровищам.
Такая ситуация приключилась со мной этим летом. И она заставила меня пересмотреть подход к прогнозированию в “Госбазе”.
Поле было «пустым», я злился и ничего не находил.
Я присел на краю поля, давая себе время осмыслить картину. Глаза зажмуривались от яркого солнца, а в голове складывалась карта аномалий.
С северной стороны, у проселочной дороги, мне везло на сталинские монеты. С южной — попадались павловские пятаки. Но само поле молчало, будто вымерло. И тогда меня осенило: а что, если когда-то здесь пролегала старая дорога? Та самая, что соединяла два поселения? Достаю телефон, открываю карту, мысленно провожу линию между точками своих прошлых находок. Да, логика есть…
Второй момент: местные старожилы говорили, что здесь когда-то было болото. Век назад? Два? Почва до сих пор хранила его следы — высокая минерализация сбивала показания прибора. Нужно было сбросить чувствительность, изменить режим поиска.
Третий фактор — время. Я знал, что тесть скоро начнет дисковать это поле. Идти за плугом — все равно что читать только что раскрытую книгу. Глубина, чистота сигнала — всё иначе.
Четвертое — поле на отшибе. Сюда наверняка уже наведывались «чёрные копатели» с их дешёвыми «Теккнами» и «Эквиноксами». Потом приезжали ребята с «Деусами» и «МайнЛабами». Они сняли вершки, думая, что выбрали всё.
А я… я прошёл там, где прошли они. Но с перенастроенным вторым «Дэусом», с другой программой, с пониманием ландшафта. И там, где другие видели помехи, мой прибор выдал чёткий, уверенный сигнал. Глубина заставила сердце зайтись — полтора штыка, не меньше.

И вот она — идеальной сохранности монета. Не золотая, но ценность её была в другом. Она была доказательством. Того, что нужно думать, а не бегать. Понимать, а не тыкаться наугад. Искать там, где другие уже побывали, но недосмотрели.
Вот так и с клиентами. Можно ходить по протоптанным тропам и собирать крохи. А можно включить голову — и найти там, где, казалось, уже пусто.
О чём это говорит:
-
Остановись и подумай.
-
Знай свой прибор.
-
Не сдавайся.
Госбаза — ваш цифровой детектор клиентов нового поколения
Металлоискатель никогда не скажет вам прямо, что скрыто в земле. Он лишь даёт намёки: состав почвы, силу сигнала, глубину залегания, характер вибрации. Окончательное решение — копать или пройти мимо — всегда остаётся за вами.
Так же работает и «Госбаза». Она не даёт стопроцентных ответов и не предсказывает будущее. Но она собирает, анализирует и показывает вам десятки признаков: динамику выручки, историю побед, профиль заказчиков, тематику участия. А дальше — ваша очередь. Ваша интуиция, опыт и готовность рискнуть.
Бывают дни, когда кажется, что всё идёт не так. Открываешь прогноз — видишь компанию, которая «не в тему». Переключаешься на следующую — и там сомнительный вариант. Возникает чувство, будто платформа «не работает», а ты тратишь время впустую.
Знакомая картина? Та же история происходит в поле с детектором в руках: сплошная «чернина», ни одного намёка на цель, и в голову закрадываются предательские мысли: «Может, прибор сломан? Может, я просто не умею?»
Но проблема редко в инструменте. Чаще — в нашей готовности доверять данным, делать выводы и действовать, даже когда сигнал кажется слабым. Успех приходит к тем, кто умеет читать между строк, совмещать машинную логику с человеческой интуицией и… иногда копать там, где другие уже прошли мимо.
Я выработал свой способ борьбы с такими сомнениями. Я просто ставлю себе задачу: проверить десять заведомо бесперспективных целей. Щёлк — гвоздь, щёлк — железный хлам, щёлк — осколок алюминия. Если все десять сигналов оказываются пустышками — значит, система работает идеально. Это как ритуал очищения: после такого я снова начинаю доверять своему инструменту. До следующих сомнений.
И вот представьте: «Госбаза» показывает, что победу одержала компания «А». А ваше чутьё, основанное на опыте, упрямо твердит: нет, здесь должна быть компания «Б». Самый простой и гениальный выход — просто позвонить в компанию «Б». И тогда вы получите не просто звонок, а подтверждение своей правоты или неправоты. И это тот самый опыт, который дорогого стоит.
Две стратегические модели
«Госбаза» прогнозирует аукцион на всём протяжении его жизненного цикла — от размещения до заключения контракта. Стратегически это два этапа:
-
Раздел «Участники» — здесь аукцион находится с момента размещения до протокола.
-
Раздел «Победители» — здесь аукцион после выхода протокола с номером победившей заявки и до конца.
Важные моменты:
-
Аукцион не может быть одновременно в «Победителях» и «Участниках» — он может находиться только в одном разделе. Поэтому при поиске прогноза нужно знать: вышел протокол или нет — и искать в соответствующем разделе.
-
После выхода протокола аукцион убирается из «Участников» и переходит в «Победители».
-
Бывает, что на этапе подачи и рассмотрения заявок база не может сделать прогноз, и до протокола его нет в «Участниках». Но как только протокол выходит — он сразу появляется в «Победителях».
-
Если аукцион появился в прогнозе «Участники», он всегда перейдёт в «Победители» после протокола.
Физически эти два раздела нельзя объединить в одну базу, потому что они используют разные модели прогнозирования с разными наборами признаков. С течением «жизни» аукцион, как любое существо, обогащается новыми признаками, которые уточняют прогноз.
Например, когда аукцион только появляется, у нас есть только базовые признаки. Но по мере его «взросления» мы начинаем понимать, как компании заявляются на него, сколько их, как они конкурируют и «давят» друг друга, насколько номера заявок понижают цены. Мы не знаем конкретные компании — только номера заявок. Но это информация, и мы можем и должны её использовать, отслеживая характер поведения и агрессивность ставок компаний в рамках заказчиков и тематики.
Так куда звонить-то: по «Победителям» или по «Участникам»?
Вот вопрос, который преследует меня в личных сообщениях, на совещаниях и даже в лифте офиса.
Лично я голосую за раздел «Участники». Это как прийти на вечеринку первым — ещё не шумно, все трезвые, и можно успеть пообщаться с кем угодно. Компании здесь ещё не зазвонены до дыр, можно обзвонить несколько из одного аукциона и даже заранее выяснить, кто во что играет. 😊
Правда, есть нюанс: по умолчанию «Участники» показывают вчерашние аукционы. Представьте: заказчик только вчера объявил тендер на ноутбуки, а компания «А» когда-то ему их поставляла. Стоит ли звонить прямо сейчас? Может, лучше подождать до момента, когда подача заявок вот-вот закроется? Фильтры, друзья мои, не забывайте про фильтры — они ваши лучшие друзья в этом хаосе.
А вот «Победители» — это уже серьёзная лига. Тут включается режим «я должен быть первым, быстрым и точным».
Да, слышал, что где-то там, в тёмном уголке интернета, торгуют «реальными протоколами победителей». Заманчиво? Ещё бы! Хочется сразу ринуться в бой: «Позвоню всем первым, съем всю рыбку, покачаюсь на люстре и, может, даже спою с дирижёром Большого театра!».
Но вот незадача — все эти «супер-базы» живут меньше, чем шаурма на вокзале, до первой проверки. А люстры, как показывает практика, имеют досадную привычку обрушиваться ровно в тот момент, когда вы начинаете на них лихо раскачиваться. Особенно — хрустальные. Они летят вниз с прекрасным звоном — с потолком, вашими надеждами и репутацией «первопоздравителя».
Так стоит ли игра свеч? Конечно, да! Если, конечно, вы уже придумали, чем будете заниматься утром после того, как ваша «волшебная база» благополучно отправится в цифровое небытие. Например — собирать осколки.
Всех участников закупок можно разделить на три типа:
-
Проверенные поставщики — те, кто уже работал с этим заказчиком.
-
Новые игроки для заказчика — те, у кого есть опыт госзакупок, но с этим конкретным заказчиком они ещё не работали.
-
Дебютанты — те, кто вообще впервые участвует в закупках (как правило, это одноразовые компании, которые либо исчезают после первой сделки, либо переходят в первую или вторую категорию).
«Госбаза» уверенно предсказывает первые две категории и — внимание! — даже третью.
«Как? — воскликнете вы. — У них же нет истории участия! Это же слепые зоны!»
Но, уважаемые присяжные, вы мыслите слишком прямолинейно. У нас есть реестр аккредитованных поставщиков. А раз есть — почему бы его не использовать?
Мы просто берём компании-дебютантов, впервые победившие в закупках, и задаёмся вопросом: откуда они появились? Кто их акционеры? С кем они связаны?
Оказывается, даже у «неписаных историй» есть свои предисловия. Главное — уметь их читать.
Вот почему я всегда настаиваю: если видите в «Госбазе» высокий шанс победы — особенно у компании с единичными победами — не мешкайте. Это не просто статистика. Это горячий след. Тот самый, за которым охотятся все, кто привык рисковать и раскачивать люстры вместо того, чтобы строить систему.
Но мы с вами не из их числа. Наша стратегия — не азартная игра, а точный расчёт. Мы не ждём у моря погоды и не надеемся на удачу. Мы живём с осознанием: «завтра реестр закроется», «послезавтра контракт подпишут», «через три дня конкуренты уже будут обзванивать победителя».
Наш трон — не хрупкая люстра, а прочная скала. Каждый такой звонок, каждая проверенная гипотеза, каждая итерация — это шаг вверх. Мы не качаемся от ветра перемен — мы управляем ими. И с каждым разом становимся только точнее, быстрее и сильнее.
Как мы предсказываем победу и как с этим работать
Многие уверены, что наш прогноз — это просто список тех, кто раньше поставлял тот же товар тому же заказчику. Знаете, такая мысль меня всегда веселит — она такая… милая и простая, как детский рисунок карандашом на салфетке.
Спешу раскрыть карты: да, компании, которые ранее поставляли, скажем, помидоры этому заказчику, действительно становятся основой. Назовём это СТАРТОВЫМ ВЕКТОРОМ — той самой точкой, от которой мы отталкиваемся. Но если бы всё было так просто, я бы давно уже разбогател на ставках, а не писал вам эти письма!
Допустим, объявлен тендер на поставку помидоров. Если бы мы просто взяли всех поставщиков томатов, огурцов, овощей и вообще сельхозпродукции в истории (видите, как я размахнулся?), и попытались угадать, кто выиграет конкретно этот тендер — нас ждало бы фиаско громче, чем провал нового сезона «Игры престолов».
Так что да, мы начинаем с того, кто поставлял помидоры вчера. Но заканчиваем тем, кто будет поставлять их завтра — и это далеко не всегда один и тот же человек!
Прогноз — это искусство последовательного приближения
Почему мы используем исторических поставщиков как отправную точку? Всё просто — математика не врёт! Цифры показывают, что более 50% победителей уже танцевали на этом балу — то есть имели опыт поставок именно этому заказчику.
Проще говоря: когда объявляется аукцион на поставку помидоров, мы анализируем историю и видим, что этот заказчик ранее работал с тремя поставщиками томатов. В более чем половине случаев победитель окажется среди этих трёх компаний. Он может быть первым в списке, последним или где-то посередине — но факт остаётся фактом: в 50%+ случаев ответ уже скрыт в исторических данных.
Это не магия — это математическая закономерность. Мы просто научили алгоритм видеть эти закономерности там, где человеческий глаз замечает лишь разрозненные факты.
Первый шаг: от статистики к стратегии
Когда вы говорите, что наш прогноз — просто статистика прошлых сделок, вы правы. Но лишь отчасти. Это только первый шаг, отправная точка в сложном алгоритмическом танце, который ведёт нас к истинному победителю.
Да, мы начинаем с анализа: смотрим, кто поставлял этому заказчику томаты, и с уверенностью можем сказать — в каждом втором случае победитель уже прячется в этом списке. Это хороший старт, но недостаточный для настоящей победы.
Что же дальше?
-
Ранжирование. Если компания уже в списке — алгоритм определяет, какая из них имеет наибольшие шансы здесь и сейчас.
-
Расширение. Если нужного поставщика в списке нет — мы ищем тех, кто мог остаться «в тени» истории, но обладает всеми признаками будущего победителя.
-
Фильтрация. Важно не только добавлять, но и безжалостно удалять тех, чьи шансы стремятся к нулю. Даже если они были в игре ранее.
-
Предвидение. Самый сложный уровень — находить дебютантов: компании без истории, но с высоким потенциалом. Да, и такое возможно.
И да, «Госбаза» справляется со всеми этими задачами. Это не просто архив данных — это живой организм, который учится, ошибается, но всегда движется к самой точной версии прогноза.
Второй эшелон: когда данные начинают думать
Мы подошли к ключевому моменту — переходу от простого списка к вероятностной модели. Теперь речь идет не просто о том, «кто поставлял», а о том, «кто вероятнее всего победит на этот раз».
Простой пример — два поставщика томатов одному заказчику:
-
ООО «Помидор» (последняя поставка — 2024)
-
ООО «Сельхоз» (последняя поставка — 2022)
Свежесть поставок — мощный сигнал. Если упростить до предела, то наш алгоритм начинает именно с этого — он ставит «Помидору» с его поставкой 2024 года гораздо более высокий начальный «вес», чем «Сельхозу» из 2022 года.
Да — последний поставщик имеет фору. Но побеждает в тендере не тот, у кого была фора, а тот, кто в конкретный момент времени оказался сильнее по совокупности множества параметров. Мы не просто констатируем прошлое — мы вычисляем настоящее, чтобы предсказать будущее.
Поэтому мы не просто смотрим на даты. Мы создаем динамическую модель, где:
-
Каждый поставщик получает первоначальный «вес»
-
Алгоритм постоянно корректирует вероятности
-
Учитываются множество факторов: от активности компании до сезонности. Принимается по внимание даже обратная связь от роботов, обзванивающих компании о их заинтересованности в банковских услугах!
Система просчитывает варианты. И с каждым новым данным наше «второе приближение» становится всё точнее. Это уже не просто статистика — это интеллектуальная система принятия решений в реальном времени.
Однако мы не можем просто сказать алгоритму: «вот список, тут лидер, а эти — аутсайдеры». Машине нужны точные цифры для работы.
Поэтому вероятности распределяются по чётким правилам:
-
Компания с самой свежей поставкой получает статус «фаворита» с базовой вероятностью 90%
-
Остальным участникам исторического списка вероятность назначается в диапазоне от 1% до 90%
Но на этом работа не заканчивается — начинается самое интересное. Алгоритм запускает итеративный процесс уточнения, в ходе которого вероятности постоянно пересчитываются на основе новых данных.
Визуально это отражается через систему индикаторов:
-
 Кружок со стрелками — сигнал, что вероятность компании превысила 90%
Кружок со стрелками — сигнал, что вероятность компании превысила 90% -
Если таких несколько — они занимают верхние позиции в прогнозе
-
 Значок 100% — появляется при достижении порога в 99%, после чего все остальные участники скрываются для избежания информационного шума
Значок 100% — появляется при достижении порога в 99%, после чего все остальные участники скрываются для избежания информационного шума
Таким образом, система не просто показывает статичные данные — она ведёт живую аналитическую работу. Это не гадание на кофейной гуще, а математический аппарат в действии.
Алгоритм фокусировки: как система помогает сделать выбор
Разберём реальный пример — аукцион № 0351300159025000184 на поставку медицинских укладок для оказания помощи при желудочно-кишечном кровотечении.
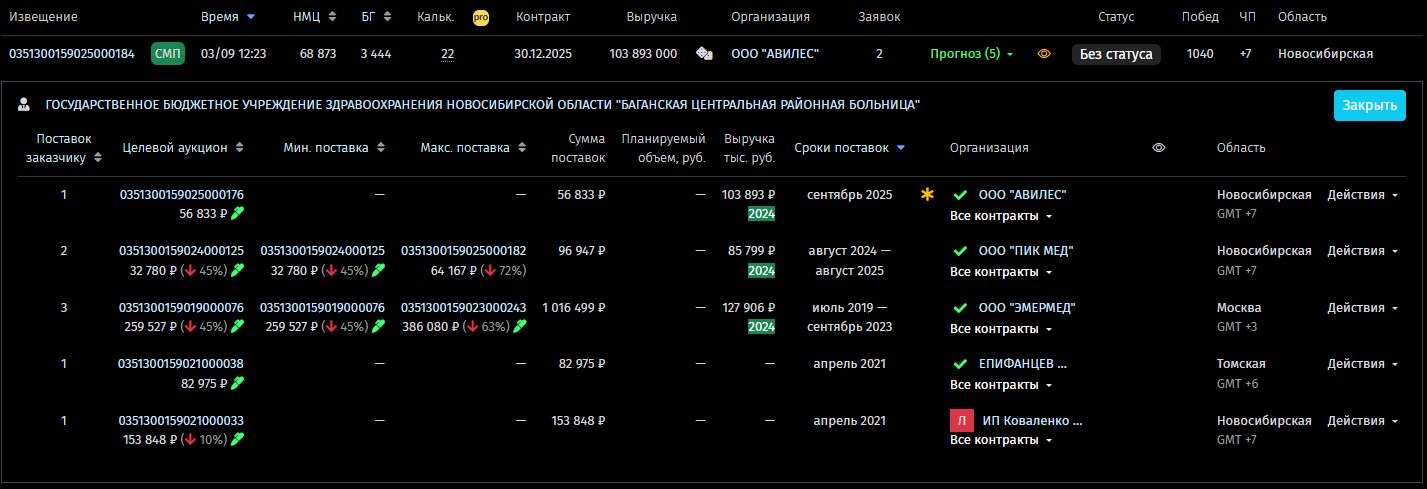
Изначально система сформировала список компаний, которые ранее работали с этим заказчиком в медицинской сфере. Обратите внимание на иконку «кубики» в сомой первой строчке — это сигнал, что прогноз ещё сырой, и ни у кого из кандидатов нет уверенных 90%.
Список отсортирован по дате последней поставки:
-
Авилес — самый свежий контракт (услуги мед. назначения)
-
Пик Мед — чуть раньше, но два контракта
-
Эмермед — ещё раньше, но три контракта
-
Епифанцев — и давняя история, и всего одна поставка
Ключевой вопрос: кому звонить в первую очередь? Система не даёт готового ответа, но предоставляет все данные для принятия решения.
Здесь включается механика «фокуса внимания» — алгоритм анализирует не только даты, но и:
-
степень тематического соответствия прошлых поставок
-
активность компании в смежных аукционах
-
динамику изменения их совместного рыночного поведения
Это уже не просто сортировка по убыванию даты последней поставки — это многофакторный анализ, который смещает фокус внимания не на того, кто был последним, а на того, кто действительно с наибольшей вероятностью выиграет именно этот тендер. Система не гадает — она взвешивает.
Решить проблему выбора можно с помощью тематического анализа выполненных аукционов. Достаточно поводить мышью по колонке «Целевой аукцион». Мы сразу видим, что «Авилес» больше всего тематически подходит — подсказка насыщена красным шрифтом.
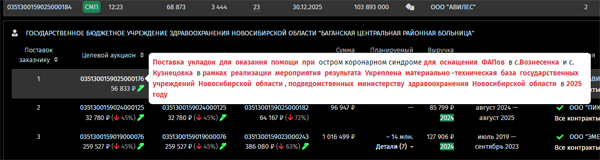
С другой стороны, и «Пик Мед», и «Эмермед» тоже поставляли эти укладки. Даже «Епифанцев» поставлял медицинские изделия, коими укладки и являются, на что указывает подсказка:

«Фокус внимания»
Чтобы избавить вас от терзаний при выборе, я создал алгоритм, который сам подсвечивает наиболее перспективную компанию для первого звонка.
Этот алгоритм я назвал «Фокус внимания». Он работает как ваш личный эксперт-консультант, который смотрит через плечо и говорит: «Видишь эту цель? Сигнал выглядит подозрительно для обычного гвоздя. Стоит проверить именно здесь».
Система анализирует сотни параметров в реальном времени, оценивая не только историю поставок, но и текущую активность компании, её рыночное поведение и даже косвенные признаки готовности к участию в тендере. Она находит те самые аномалии в данных, которые указывают на высокую вероятность победы именно этого поставщика.
Фактически, алгоритм делает за вас ту самую аналитическую работу, на которую обычно уходят часы рутинного анализа — и выдаёт готовый приоритизированный список действий. Вам остаётся только сделать звонок.
Вернемся к нашему аукциону с укладками. Первоначальный прогноз дал нам четырех кандидатов. Алгоритм «Фокуса внимания» начинает задавать вопросы и искать ответы в данных:
-
Временной фактор: «Авилес» поставлял недавно. Но что именно? Алгоритм видит, что его последние поставки — специализированные наборы. Вес вероятности «Авилес» резко возрастает.
-
Тематическое ядро: «Пик Мед» и «Эмермед» поставляли давно, но что именно? Алгоритм глубоко анализирует контракты и КТРУ. Он обнаруживает, что «Эмермед» поставлял хирургические и реанимационные наборы, а «Пик Мед» — более широкий ассортимент. Вес «Эмермед» снижается.
-
Активность участника: Алгоритм проверяет, подавал ли кто-то из этих поставщиков заявки на похожие аукционы у других заказчиков в последнее время. Оказывается, «Епифанцев» только вчера выиграл тендер на аналогичные укладки в соседнем регионе.
-
Поведенческий анализ: Система смотрит на номера. Она видит, что компания с номером заявки №2 (условно, «Авилес») любитель сильно снижать цену когда побеждает. Это классическая поведенческая модель победителя.
В результате этого анализа алгоритм «Фокус внимания» присваивает каждой компании новую, уточненную вероятность. И теперь в интерфейсе вы видите не просто статичный список, а динамическую картину:
-
« Авилес» получает значок желтой звездочки. Алгоритм уверен и рекомендует.
-
«Пик Мед» и « Эмермед» остаются в списке, но их вероятность падает ниже 90%. Они отодвигаются ниже. Но они — сильные претенденты.
-
«Епифанцев» — слабый претендент, и «темная лошадка».
Ваше действие теперь очевидно и обоснованно данными: первый звонок — «Авилесу», второй, на всякий случай, — «Пик Меду» или « Эмермеду».
✨ Убедитесь, как «Фокус внимания» экономит ваше время! Зайдите в раздел «Победители» и найдите любой активный аукцион. Обратите внимание на желтый значок-звездочку 🟉 — это и есть рекомендация алгоритма. Сравните, насколько целевыми были компании, отмеченные им, по сравнению с теми, что вы выбирали интуитивно.
Тематическое ядро
«Госбазу» можно сравнить с масштабным литературным произведением. Каждая компания-участник закупок здесь — это отдельное слово, обладающее своим значением и весом. Подобно тому, как слова складываются в предложения, алгоритмы системы выстраивают компании в сложные цепочки — логические последовательности их участия в торгах у конкретных заказчиков.
Эти «предложения» из контрактов и сделок образуют развернутые повествования и формируют сложный, многоголосый нарратив рынка. Они рассказывают нам многолетние саги о партнёрстве, взлётах и падениях, стратегическом планировании и рыночных битвах.
Это истории о сотрудничестве, доверии и рыночных стратегиях. История о том, как небольшая фирма, начав с крошечных муниципальных заказов, шаг за шагом росла, наращивала экспертизу и превращалась в ключевого поставщика для крупного государственного холдинга. Или драматичный рассказ о новичке, который ворвался на рынок, перехватив контракт у матерых игроков благодаря идеальному сочетанию цены и качества.
Задача аналитика — стать внимательным читателем, который улавливает не только очевидный сюжет, но и скрытые смыслы, иронию и предзнаменования будущих глав. Умение читать и интерпретировать эти истории и отличает рядового менеджера от стратега, способного предугадать развязку ещё до того, как будет поставлена последняя точка в виде подписанного контракта.
Все эти слова-компании расположены в огромном смысловом кластере многомерного пространства как математические векторы. И так же, как слова в языке могут быть синонимами, антонимами или просто находиться на разной смысловой дистанции, алгоритмы «Госбазы» вычисляют «семантическую близость» компаний, определяя их похожесть через операции над векторами — скалярное умножение, расчёт косинусного расстояния и другие методы.
Это позволяет системе находить не только прямых конкурентов, но и компании, способные стать надёжными поставщиками, выявлять скрытые паттерны кооперации или, наоборот, стратегического избегания определённых рынков. Математика превращается в лингвистику рынка: если два вектора-компании имеют малый угол между собой — они работают в одной нише, с похожими заказчиками, по сопоставимым ценам.
Таким образом, «Госбаза» становится не просто сборником данных, а настоящим «переводчиком» сложных рыночных взаимоотношений. Она позволяет увидеть за сухими цифрами контрактов живую ткань экономических связей — и предсказать, какое «слово» будет произнесено следующим в непрерывном повествовании госзакупок.
Мне часто задают вопрос: почему та или иная компания прогнозируется к победе с более высокой вероятностью? Людям бывает сложно понять логику алгоритма.
Мы, живущие в трёхмерном пространстве, с трудом можем визуализировать даже четвёртое измерение. Чтобы по-настоящему ощутить его, нужно мысленно пройти через все “кубические” единицы трёхмерного мира — например, осознать время как полноценное измерение, а не просто последовательность событий.
Так же и с прогнозированием: алгоритм оперирует десятками “измерений” — факторов и признаков, невидимых человеческому глазу. То, что нам кажется неочевидным выбором, для системы является закономерным результатом сложных математических вычислений в многомерном пространстве данных.
Пора буквально перейти в другое измерение
Если вы или ваша система до сих пор ищите похожий аукцион компании по названию и КТРУ и прогнозируете на основании результата победу или участие компаний, то вы ищите потерянные ключи только под фонарём, потому что там светлее. Да, найти что-то можно, но вряд ли то, что нужно.
Такие системы выдают гору мусора и маскируют его под релевантность. Происходит:
-
Иллюзия выбора: Вам показывают 100 «похожих» аукционов или поставщиков. Вы успокаиваетесь — «система работает». Но 90 из них — это либо из другой отрасли, либо с другим масштабом, либо с иными условиями.
-
Пропуск реальных возможностей: Пока вы листаете 5 страниц с «йогуртами для детсадов» (потому что в названии было слово «молоко»), вы пропускаете лот «Закупка сыра „Моцарелла“» — который идеально подходит в прогноз победы, но название не совпало.
-
Потеря доверия: После десятого нерелевантного результата пользователь перестаёт верить системе вообще. «Ну, опять эта база ерунду показала».
Почему другие системы прогноза так делают?
Потому что это дёшево и быстро. Научить алгоритм искать по совпадению слов — дело пары дней. А чтобы научить его понимать смысл — нужны месяцы работы и компетенции.
Это как лечить болезнь по заголовку в Википедии, не читая симптомов. Сработает в одном случае из ста, но в остальных девяноста девяти вы либо пропустите проблему, либо начнёте лечить не то.
Прогнозы, работающие только по названию и КТРУ, — это не инструмент для поиска, а генератор иллюзий. Они создают видимость работы, но не дают реального результата. Настоящий анализ начинается там, где заканчиваются ключевые слова и начинается семантика.
Серьёзно, это крайне ненадёжный подход, примерно как пытаться оценить содержание книги только по обложке.
1. Синонимы и разнообразие формулировок
Один и тот же предмет закупки могут называть десятками способов.
Пример:
-
Аукцион 1: «Поставка молочной продукции для школ»
-
Аукцион 2: «Закупка продуктов переработки молока для образовательных учреждений»
-
Аукцион 3: «Йогурты, творог, кефир для столовых СОШ»
Проблема: Названия разные, но суть одинаковая. Косинусное сходство текстов может быть низким, хотя аукционы идентичны по смыслу.
2. Омонимы и двусмысленности
Одинаковые слова могут означать совершенно разное в разных контекстах.
Пример:
-
Аукцион 1: «Поставка систем охлаждения для серверных стоек» (ИТ)
-
Аукцион 2: «Ремонт систем охлаждения в цехе молочного комбината» (промышленность)
-
Аукцион 3: «Разработка системы охлаждения двигателя» (автопром)
Проблема: Ключевое слово «охлаждение» есть везде, но аукционы из разных отраслей. Сходство по названию будет обманчивым.
3. Ключевые слова против деталей
В названии может не быть важных параметров: бренда, модели, технических характеристик.
Пример:
-
Аукцион 1: «Ноутбуки для офиса» (закупка 100 устройств Dell)
-
Аукцион 2: «Ноутбуки для сотрудников» (закупка 10 игровых ASUS)
Проблема: Названия почти идентичны, но масштаб, цена и специфика — разные.
4. Опечатки и нестандартные сокращения
Пример:
-
«Краска масляная МА-15» → «Краска МА15» → «Краска маслянная МА-15»
-
«Прибор для измерения давления» → «Давомер» (опечатка) → «Тонометр»
Проблема: Человек видит совпадение, но алгоритм не поймёт, что это одно и то же.
5. Коды против названия
Часто в названии пишут код КТРУ/ОКПД2, но не пишут суть.
Пример:
-
Аукцион 1: «Поставка 32.99.11.120» (это код для… сахара-рафинада!)
-
Аукцион 2: «Закупка сахара-песка» (другой код, но тема похожая)
Проблема: Человек видит совпадение, алгоритм — нет.
Когда это может сработать?
Только в очень узких случаях:
-
Если все названия стандартизированы (например, шаблоны одного заказчика).
-
Для грубой предварительной фильтрации (но потом всё равно нужен ручной разбор).
Что делать вместо этого?
Применять NLP-модели, обученные на описаниях аукционов — они улавливают контекст и комбинировать метрики: цена, регион, категория, история заказчика и другие.
Сравнивать аукционы только по названию — это как выбирать автомобиль по цвету, игнорируя двигатель, цену и пробег. Можно случайно закупить розовый спорткар вместо белого грузовика 😄
Следующий раздел — для особо любознательных. Если вам не интересны технические детали — смело пролистывайте до раздела «Тактика работы с прогнозом».
Многие спрашивают меня: “Максим, как сделать такой же точный прогноз? Это же наверное миллионы строк кода, нейросети с тремя докторскими и серверная ферма, которая греет соседний район!”
Я смотрю на них, вздыхаю и говорю: "Друзья, вы не поверите. Вся Госбаза, по сути, состоит из одной единственной функции." 😊
И эта функция — косинусное сходство. Та самая, которая сравнивает не числа, а направления. Как компас, который показывает, куда смотреть, а не как далеко бежать.
Вот смотрите, как это выглядит в коде:
import math
def gosbase_similarity(a, b):
"""Вся магия Госбазы в одной функции!"""
dot_product = sum(a_i * b_i for a_i, b_i in zip(a, b))
magnitude_a = math.sqrt(sum(x * x for x in a))
magnitude_b = math.sqrt(sum(x * x for x in b))
return dot_product / (magnitude_a * magnitude_b) if magnitude_a * magnitude_b != 0 else 0
А вот как это работает на примере двух поставщиков:
# Поставщик А: работал с госзаказчиком, низкая цена, близкий регион
supplier_a = [0.9, 0.8, 0.7] # [опыт с заказчиком, цена, близость региона]
# Поставщик Б: новый участник, средняя цена, далекий регион
supplier_b = [0.1, 0.5, 0.2]
# Считаем "похожесть" на идеального победителя
ideal_winner = [1.0, 0.9, 0.8] # [максимальный опыт, минимальная цена, максимальная близость]
similarity_a = gosbase_similarity(supplier_a, ideal_winner) # ≈ 0.997
similarity_b = gosbase_similarity(supplier_b, ideal_winner) # ≈ 0.483
Вы спросите: “И это всё?!”. А я отвечу: “Нет, конечно не всё!”
Потому что перед этой функцией идет:
- Векторы не из 3, а из 300+ параметров
- Есть предобработка данных и нормализация
- Механизмы внимания и проверки на аффилированность
- И моя любимая кофемашина, без которой ничего не работает ☕
Но философия остаётся прежней: мы не предсказываем будущее, а находим похожие ситуации из прошлого. Это как смотреть на тендер через призму тысячи уже состоявшихся аукционов.
Так что если хотите повторить успех Госбазы — начинайте с косинусов. А когда доползете до PCA и трансформеров — зовите, будем вместе кофе пить! 😉
SQL-запрос — это не искусственный интеллект
Когда-то я думал, что прогноз — это просто. Достаточно взять прошлых победителей заказчика и выдать их за прогноз на будущее. Получалось красиво, точно… и неверно в 70% случаев. Это как пытаться угадать погоду, глядя в окно: «Вчера было солнце — значит, и сегодня будет». А на улице — метель.
Все, кто до сих пор прогнозируют по принципу Select * from purchases where customer_inn='1234567890' and okpd2 like'22%' — занимаются иллюзией анализа. Они как археологи, которые раскапывают один и тот же камень и каждый раз удивляются: «И что, тут опять нет золота?»
Они застряли в прошлом. В эпохе, когда:
-
Данные были копилкой, а не компасом
-
SQL-запрос считался искусственным интеллектом
-
Сравнивать умели только даты и цифры в столбиках
-
Угадывали по принципу «в прошлый раз сработало»
Это как назвать велосипед — «гиперкар». Или зажигалку — «управляемым термоядерным синтезом». Звучит громко, но на деле — просто красивые слова.
SQL отлично справляется с фильтрацией по жёстким условиям: WHERE price < 100000 AND region = 'Moscow'. Но как только мы хотим найти «похожие» закупки, мы сталкиваемся с ограничениями.
Проблема не в SQL, а в самой природе задачи. SQL оперирует категориями («равно/не равно»), а для прогноза нужны степени похожести («насколько близко?»).
Именно здесь мы используем косинусное сходство. Оно не лучше SQL — оно решает принципиально другую задачу: вычисляет не явное совпадение, а меру сходства в пространстве из сотен параметров.
SQL дал нам данные, а наш алгоритм показал скрытые в них связи.
Ситуация: Закупка ноутбуков для школы в Москве.
Обычный подход:
SELECT * FROM suppliers
WHERE region = 'Moscow'
AND product_type = 'notebooks'
→ Найдёт 500+ поставщиков, непонятно кого выбрать.
Наш подход:
# Сравниваем по ключевым параметрам
tender_vector = [0.9, # заказчик - школа
0.8, # бюджет до 1 млн
0.7, # сроки сжатые
0.9] # Москва
# Ищем в истории БАЗЫ
similar_tenders = find_similar(tender_vector,
history=all_tenders_3_years,
threshold=0.85)
Результат: Система находит 12 похожих случаев, где в 10 из них побеждали молодые компании из Подмосковья с оборотом до 50 млн — хотя они никогда раньше не поставляли именно этому заказчику!
- Мы ищем не по жёстким критериям, а по степени похожести
- Учитываем не только реестр контрактов, но и:
- Активность компаний в смежных тендерах
- Динамику изменения цен
- Косвенные признаки готовности к участию
- Понимаем контекст: например, что закупка в декабре для школы — вероятно, к началу третьей четверти
В этой модели мы по праву можем “играться” с параметрами как дети в песочнице — только вместо ведерка и лопатки у нас вектора и коэффициенты. Например, в прогнозе для коммерческих аукционов близость региона поставки критически важна.
Попробуйте сделать это через SQL-запросы — это как лечить мигрень танцем с бубном. Вроде и движения правильные, и звук приятный, но голова болит еще сильнее.
-- Попытка найти ближайших поставщиков через SQL (адский вариант):
SELECT * FROM suppliers
WHERE region_distance < 100
AND product_category = 'печеньки'
AND... (список из 20 условий, после которых хочется стать отшельником)
А теперь смотрим на векторный подход:
Допустим, у нас есть 3 региона:
- Москва (центр: 55.75, 37.61)
- Санкт-Петербург (центр: 59.93, 30.31)
- Владивосток (центр: 43.11, 131.87)
Шаг 1: Рассчитаем расстояния между ними (в км, например, по формуле Хаверсина)
- Москва – СПб: ≈ 635 км
- Москва – Владивосток: ≈ 6430 км
- СПб – Владивосток: ≈ 6550 км
Шаг 2: Нормализуем расстояния (приведём к диапазону 0–1)
Максимальное расстояние в России (Калининград – Владивосток) ≈ 7500 км.
Делим все расстояния на 7500:
- Москва – СПб:
635 / 7500 ≈ 0.085 - Москва – Владивосток:
6430 / 7500 ≈ 0.857 - СПб – Владивосток:
6550 / 7500 ≈ 0.873
Шаг 3: Создаём вектор для каждого региона
Каждый регион представляется вектором близости к другим регионам.
Например, для Москвы:
- Близость к Москве:
1.0(полная идентичность) - Близость к СПб:
1 - 0.085 = 0.915(чем ближе, тем выше число) - Близость к Владивостоку:
1 - 0.857 = 0.143
Вектор Москвы: [1.0, 0.915, 0.143]
Аналогично:
- Вектор СПб:
[0.915, 1.0, 0.127](близость к Владивостоку:1 - 0.873 = 0.127) - Вектор Владивостока:
[0.143, 0.127, 1.0]
Пример сравнения двух контрактов с такой кодировкой
Контракт №1: Поставка ноутбуков в Москве
Контракт №2: Поставка ноутбуков в СПб
Параметры:
- Категория товара: ноутбуки = 1.0
- Цена: 5 млн → 0.5 (нормализованная)
- Регион: Москва =
[1.0, 0.915, 0.143], СПб =[0.915, 1.0, 0.127]
Вектор контракта №1 (Москва):
[1.0, 0.5, 1.0, 0.915, 0.143]
Вектор контракта №2 (СПб):
[1.0, 0.5, 0.915, 1.0, 0.127]
Считаем косинусное сходство:
-
Скалярное произведение:
(1.0*1.0) + (0.5*0.5) + (1.0*0.915) + (0.915*1.0) + (0.143*0.127) ≈ 1 + 0.25 + 0.915 + 0.915 + 0.018 ≈ 3.098 -
Длины векторов:
|A| = √(1² + 0.5² + 1² + 0.915² + 0.143²) ≈ √(1 + 0.25 + 1 + 0.837 + 0.02) ≈ √3.107 ≈ 1.763
|B| = √(1² + 0.5² + 0.915² + 1² + 0.127²) ≈ √(1 + 0.25 + 0.837 + 1 + 0.016) ≈ √3.103 ≈ 1.762 -
cos(θ) = 3.098 / (1.763 * 1.762) ≈ 3.098 / 3.106 ≈ 0.997
💡 Результат: cos(θ) ≈ 0.997 → контракты практически идентичны, как и должно быть (один товар, близкие регионы).
Возьмем два кардинально разных контракта и посчитаем их сходство.
Контракт №1: Поставка ноутбуков в Москве
Контракт №3: Ремонт кровли в Владивостоке
Параметры:
- Категория товара: Ноутбуки = 1.0, Ремонтные работы = 0.1
- Цена: 5 млн → 0.5 (нормализованная), 500 тыс. → 0.05
- Регион: Москва = [1.0, 0.915, 0.143], Владивосток = [0.143, 0.127, 1.0]
Вектор контракта №1 (Москва, ноутбуки):
[1.0, 0.5, 1.0, 0.915, 0.143]
Вектор контракта №3 (Владивосток, ремонт):
[0.1, 0.05, 0.143, 0.127, 1.0]
Скалярное произведение:
(1.0*0.1) + (0.5*0.05) + (1.0*0.143) + (0.915*0.127) + (0.143*1.0) = 0.1 + 0.025 + 0.143 + 0.116 + 0.143 ≈ 0.527
Длины векторов:
|A| ≈ 1.763 (как в предыдущем расчете)
|B| = √(0.1² + 0.05² + 0.143² + 0.127² + 1.0²) = √(0.01 + 0.0025 + 0.0204 + 0.0161 + 1) ≈ √1.049 ≈ 1.024
cos(θ) = 0.527 / (1.763 * 1.024) ≈ 0.527 / 1.805 ≈ 0.292
💡 Результат: cos(θ) ≈ 0.292 → контракты радикально отличаются
Угол между векторами ≈ 73° — система видят их как совершенно разные истории.
Вектора позволяют закодировать ваши самые дикие фантазии:
1. Параметры заказчика
- Доля побед «любимого» поставщика
- Средний размер НМЦК всех закупок заказчика
- Общее количество проведенных закупок за год
- Доля аукционов vs конкурсов vs котировок
- Доля расторгнутых контрактов в истории
- Доля жалоб по 44-ФЗ и 223-ФЗ
- Среднее количество участников в тендерах
- Регион
- Отрасль (образование, медицина, строительство и т.д.)
2. Параметры текущего аукциона
- НМЦК (нормализованная)
- Тип процедуры (аукцион, конкурс, котировка)
- Способ определения поставщика (электронный аукцион, запрос котировок)
- Наличие ограничений для СМП и СОНО
- Критерии оценки заявок (только цена, цена + качество)
- Срок выполнения контракта
- Наличие аванса и его размер
- Сложность предмета закупки (через NLP описания)
- Количество упоминаний брендов в описании (может указывать на конкретного поставщика)
3. Параметры участников
- Количество поданных заявок
- Средний опыт участников
- Признак «своего» поставщика (работал с заказчиком ранее)
- Географическая близость участников к заказчику
- Доля «новых» участников (кто никогда не побеждал)
- Активность участников в других тендерах этого заказчика
4. Исторические паттерны
- Динамика снижения цены в ходе аукциона
- Сезонность (например, закупки к началу учебного года)
5. Внешние данные
- Курс валют (для импортных товаров)
- Экономические показатели отрасли
- Репутация компаний из открытых источников
- Связи между юрлицами (аффилированность участников)
6. И даже самые “дикие” фантазии
- День недели публикации закупки
- Время суток публикации
- Праздничные дни рядом с датами аукциона
Пример вектора для одного аукциона:
[0.85, // Доля побед "любимого" поставщика
0.75, // Средний НМЦК заказчика
0.40, // Доля аукционов у заказчика
0.02, // Доля расторгнутых контрактов
0.60, // НМЦК текущего аукциона
0.80, // Признак электронного аукциона
0.25, // Срок выполнения
0.90, // Наличие аванса
0.10, // Сложность предмета закупки
0.75, // Количество участников
0.60, // Опыт участников
0.95, // Признак "своего" поставщика
0.30, // Географическая близость
0.80, // Активность в других тендерах
0.20, // Сезонность
... // и еще куча всего
]
Попробуйте учесть всё это в рамках SQL-запросов — задача быстро превращается в адскую головоломку. А вот с векторным подходом всё куда проще:
-
Вы передаёте системе два вектора и получаете оценку их схожести (насколько похожи два аукциона или два поставщика).
-
Вы передаёте системе один вектор и просите найти N ближайших соседей — то есть самые похожие закупки или компании.
💡 Это уже не фильтрация по жёстким условиям (WHERE price < 1 000 000 AND region = 'Москва'), а поиск по смысловой близости.
Результат — вместо 500 «кандидатов наугад» вы получаете 5–10 реально релевантных.
Сравнение госконтрактов с помощью векторных представлений
Давайте преобразуем текстовые и числовые данные каждого контракта в числовой вектор (точку в многомерном пространстве). Чем ближе эти точки друг к другу и чем меньше косинусное расстояние между их векторами, тем более похожи контракты.
Допустим, у нас есть три госконтракта:
| Параметр | Контракт №1 (“А”) | Контракт №2 (“Б”) | Контракт №3 (“В”) |
|---|---|---|---|
| Наименование | Поставка ноутбуков и оргтехники | Закупка компьютеров и мониторов | Ремонт кровли здания |
| Код категории ОКПД2 | 26.20.11.110 | 26.20.11.110 | 43.21.10.110 |
| Начальная цена (руб.) | 1 500 000 | 1 750 000 | 2 000 000 |
| Ключевые слова | ноутбук, монитор, офис |
компьютер, монитор, рабочее место |
кровля, ремонт, гидроизоляция |
Ожидаемо, что контракты А и Б должны быть очень близки (оба про IT-технику), а контракт В должен быть отдален от них.
1. Создание векторных представлений
Мы создадим для каждого контракта общий вектор, соединив несколько отдельных векторов, полученных разными способами.
Шаг 1: Векторизация текстовых полей (с помощью эмбеддингов)
Используем готовую модель для получения векторных представлений слов и предложений, например, rubert-tiny2.
- Вектор для “Наименования” и “Ключевых слов”:
- Объединим эти поля в один текст для каждого контракта.
- Пропустим этот текст через модель, чтобы получить вектор размерностью 312 (для выбранной модели).
Примерные значения (условно):
Вектор_А_text=[0.12, -0.05, 0.88, ..., 0.42](312 измерений)Вектор_Б_text=[0.11, -0.04, 0.87, ..., 0.41](очень похож на Вектор_А)Вектор_В_text=[-0.21, 0.75, -0.33, ..., -0.61](сильно отличается)
Шаг 2: Векторизация категории (ОКПД2)
Код ОКПД2 имеет иерархическую структуру.
- Создадим общий словарь всех возможных кодов в нашей выборке. Допустим, у нас есть всего 2 кода:
26.20.11.110и43.21.10.110. - Размерность вектора будет равна 2.
Векторы:
Вектор_А_okpd2=[1, 0](первая категория)Вектор_Б_okpd2=[1, 0](первая категория) идентичныВектор_В_okpd2=[0, 1](вторая категория)
Шаг 3: Нормализация цены
Цену нельзя просто добавить как есть, т.к. ее масштаб может “перевесить” другие признаки. Ее нужно нормализовать.
- Найдем макс. и мин. цену в выборке:
max=2 000 000,min=1 500 000. - Нормализуем по формуле:
(цена - min) / (max - min)
Нормализованные значения:
Цена_А_norm= (1 500 000 - 1 500 000) / 500 000 =0.0Цена_Б_norm= (1 750 000 - 1 500 000) / 500 000 =0.5Цена_В_norm= (2 000 000 - 1 500 000) / 500 000 =1.0
Теперь мы можем представить это как вектор размерностью 1:
Вектор_А_price=[0.0]Вектор_Б_price=[0.5]Вектор_В_price=[1.0]
2. Построение общего вектора контракта
Соединим все векторы в один большой для каждого контракта.
Общая размерность: 312 (текст) + 2 (ОКПД2) + 1 (цена) = 315
Вектор_А=concat(Вектор_А_text, Вектор_А_okpd2, Вектор_А_price)=[0.12, -0.05, 0.88, ..., 0.42, 1, 0, 0.0]Вектор_Б=concat(Вектор_Б_text, Вектор_Б_okpd2, Вектор_Б_price)=[0.11, -0.04, 0.87, ..., 0.41, 1, 0, 0.5]Вектор_В=concat(Вектор_В_text, Вектор_В_okpd2, Вектор_В_price)=[-0.21, 0.75, -0.33, ..., -0.61, 0, 1, 1.0]
3. Сравнение и расчет расстояний
Допустим, после всех преобразований мы получили укороченные, но репрезентативные векторы для наглядности. Вместо 315 измерений возьмем векторы размерностью 5.
Пусть наши итоговые векторы выглядят так:
Вектор_А=[0.9, 0.2, 0.8, 1.0, 0.1](Поставка IT)Вектор_Б=[0.8, 0.3, 0.9, 1.0, 0.4](Закупка IT)Вектор_В=[0.1, 0.9, 0.2, 0.0, 0.9](Ремонт)
Здесь первые три числа — усредненная суть текстового эмбеддинга, четвертое — код ОКПД2 (1 для IT, 0 для ремонта), пятое — нормализованная цена.
Косинусное сходство измеряет косинус угла между двумя векторами. Чем больше сходство, тем меньше угол.
Формула:
cos_sim(A, B) = (A · B) / (||A|| * ||B||)
где:
A · B— скалярное произведение векторов,||A||и||B||— длины векторов.
Косинусное расстояние вычисляется как:
cos_dist(A, B) = 1 - cos_sim(A, B)
Рассчитаем расстояние между Контрактом А и Контрактом Б:
-
Скалярное произведение (A · Б):
(0.9 * 0.8) + (0.2 * 0.3) + (0.8 * 0.9) + (1.0 * 1.0) + (0.1 * 0.4) =
= 0.72 + 0.06 + 0.72 + 1.0 + 0.04 = 2.54 -
Евклидова норма вектора А (||A||):
sqrt(0.9² + 0.2² + 0.8² + 1.0² + 0.1²) =
sqrt(0.81 + 0.04 + 0.64 + 1.0 + 0.01) = sqrt(2.5) ≈ 1.581 -
Евклидова норма вектора Б (||Б||):
sqrt(0.8² + 0.3² + 0.9² + 1.0² + 0.4²) =
sqrt(0.64 + 0.09 + 0.81 + 1.0 + 0.16) = sqrt(2.7) ≈ 1.643 -
Косинусное сходство (cos_sim):
2.54 / (1.581 * 1.643) ≈ 2.54 / 2.597 ≈ 0.978 -
Косинусное расстояние (cos_dist):
1 - 0.978 = 0.022
Результат: Расстояние между А и Б очень мало (~0.02), что подтверждает их сильную похожесть.
Рассчитаем расстояние между Контрактом А и Контрактом В:
-
Скалярное произведение (A · В):
(0.9 * 0.1) + (0.2 * 0.9) + (0.8 * 0.2) + (1.0 * 0.0) + (0.1 * 0.9) =
= 0.09 + 0.18 + 0.16 + 0.0 + 0.09 = 0.52 -
Евклидова норма вектора В (||В||):
sqrt(0.1² + 0.9² + 0.2² + 0.0² + 0.9²) =
sqrt(0.01 + 0.81 + 0.04 + 0.0 + 0.81) = sqrt(1.67) ≈ 1.292 -
Косинусное сходство (cos_sim):
0.52 / (1.581 * 1.292) ≈ 0.52 / 2.043 ≈ 0.255 -
Косинусное расстояние (cos_dist):
1 - 0.255 = 0.745
Результат: Расстояние между А и В велико (~0.75), что подтверждает их различие.
Этот подход позволяет гибко и точно находить смыслово близкие контракты, что полезно для:
- Поиска аналогов для оценки начальной максимальной цены контракта (НМЦК).
- Мониторинга закупок у единственного поставщика.
- Рекомендации поставщикам похожих тендеров.
- Кластеризации всех закупок организации для анализа.
Красота векторного подхода в его полной адаптивности.
Представьте, что каждый признак в векторе — это музыкант в оркестре. Сегодня солирует скрипка (например, регион поставки), а завтра — барабан (ОКПД2). Мы не просто слушаем постоянный гул — мы дирижируем! Можем усилить партию нужного инструмента, повысив вес его параметра, а можем вообще убрать флейту из композиции, снизив размерность.
Всё это позволяет нам не просто «сравнивать», а гибко настраивать модель под специфику каждой закупки, каждого поставщика и даже хоть времени года. SQL-запрос так не умеет — он как заводная игрушка, которая всегда делает одно и то же. А вектора — это живой организм, который учится, адаптируется и меняется вместе с рынком.
Тактика работы с прогнозом
Я условно делю пользователей Госбазы на три лагеря — не по статусу, а по стилю охоты за клиентами:
-
Ранние птицы (работа с «Участниками»). Фильтруйте аукционы по дате окончания подачи заявок. Не звоните по только что опубликованным аукционам. Установите фильтр «Подача заявок заканчивается через 1-3 дня». Компании в этот момент уже приняли решение об участии, у менеджеров есть информация, но самого ажиотажа еще нет. Вы будете одним из первых, но не слишком навязчивым.
-
Стрижи (работа с «Победителями»). Здесь скорость решает все. Используйте фильтр «Дата публикации протокола: Сегодня». Ваша цель — успеть позвонить в период между публикацией протокола на ЭТП и моментом, когда остальные сами начнут обзванивать победителя для уточнения деталей. Это окно — ваше ключевое преимущество.
-
Охотники за «темными лошадками». Это те самые компании, которые поставляли давно («Епифанцев» из нашего примера выше). Они менее зазвонены, и ваш звонок может стать для них долгожданным предложением о сотрудничестве, а не просто спамом.
Каждый из этих подходов рабочий. Выбирайте свой — или комбинируйте, если хотите закрывать все фронты. Главное — действовать, а не ждать у моря погоды.
Некоторые верят в единорогов. Мы — в открытость и цифры.
Я слышал, что где-то там, в туманных далях рынка, есть решения, которые предсказывают будущее с точностью 101%. Говорят, их разрабатывали 100500 разработчиков, а стоимость проекта сравнима с бюджетом небольшой лунной миссии 🚀
-
Наш прогноз: Сложный алгоритм → проверяемое предсказание → фиксация результата → публичная статистика с цифрами и процентами. Скучно? Зато честно.
-
Альтернативные “предсказания”: [Данные удалены по требованию чревовещателя] → прогноз → [Результат засекречен в целях сохранения ауры непогрешимости].
Знаете, любой рыбак у костра с радостью расскажет вам о том, какого огромного карпа он поймал на прошлой неделе. Но почему-то фото всегда оказывается размытым, а сам гигантский улов — «уже съеден». 😊 С прогнозами победителей та же история. Легко заявлять о фантастической точности, когда никто не видит вашего реального улова. Мы же ведём открытый дневник рыбака: вот наш прогноз, а вот — реальный победитель. Прямая трансляция. Без сказок.
Да, моя база, к сожалению, лишена дара ясновидения. Мы просто фиксируем каждое свое предсказание, сверяем его с реальностью и честно считаем процент сбывшихся прогнозов. Это скучно, неинтересно и совершенно лишено магии. Зато это — правда. Приходите к нам, если хотите работать с данными, а не с обещаниями.
Мы любим математику за её честность. Дважды два всегда четыре, а наш процент точности — всегда подтверждён документально. Мы оставляем загадочность для детективных романов, а в прогнозах предпочитаем прозрачность.
«Госбаза» — как поставщик смыслов
Многие клиенты просят меня сделать «кнопочку здесь» или «значёк там»… Друзья мои, это не развитие ресурса. Не то, к чему мы стремимся.
Наша глобальная идея, наш главный вектор сейчас — объяснимый прогноз. Мы не хотим быть «чёрным ящиком», который выдаёт магические цифры без смысла и причин. Мы хотим, чтобы вы понимали, а не просто верили. Чтобы вы видели не только «кто победит», но и почему именно он, какие факторы сыграли ключевую роль — цена, история, регион, связи или тематическое совпадение.
Мы работаем над тем, чтобы алгоритм не просто предсказывал, но и аргументировал своё решение — как опытный аналитик, который показывает вам расчёт и раскладывает карты на столе. Чтобы вы могли принять взвешенное решение: звонить или нет.
Наша цель — дать вам не просто данные, а инсайты. Не просто инструмент, а партнёра. И каждая следующая функция будет вести нас именно к этой цели — к прозрачности, ясности и полному контролю над процессом.
Так что в следующий раз, когда вам захочется попросить очередную «кнопочку», спросите себя: она сделает прогноз понятнее? Если да — мы уже над этим работаем. Если нет — давайте вместе думать, как решить вашу задачу иначе, глубже и стратегически верно.
Вместо множества кнопок — один точный ответ. Вместо шума данных — ясная сигнальная карта. Это наш путь.
Чтобы было понятнее. Представьте, что у вас есть куча разрозненных продуктов: мука, яйца, сахар, разбитая скорлупа на столе. И у вас есть готовый торт, который вам принесли и сказали: «Держите, это торт».
Так вот, мы стремимся к тому, чтобы давать вам инсайты — рецепты этого торта. Понимание того, почему он такой воздушный, какие именно пропорции критичны и как повторить этот успех в другой раз, заменив клубнику на малину.
Таким образом, наша цель — давать вам не просто прогноз («победит компания А»), а объяснимый прогноз — готовый инсайт, который отвечает на вопрос «почему именно она, и что это значит для меня?».
Это и есть следующая эволюция продукта: от генератора данных — к поставщику смыслов. Это колоссальное преимущество на рынке, где главная проблема — как раз необъяснимость прогнозов.
Рынок прогнозов в госзакупках затих. А когда не с кем соревноваться — работать становится… скучновато.
Но мы не умеем по-другому. Вместо того чтобы замедлиться, мы разгоняемся вдвойне. Потому что настоящая конкуренция — это не с другими, а с самим собой вчерашним. Нет ничего на свете лучше, чем соревноваться с идеальной версией себя. Спасибо, что вы с нами на этом пути.
А знаете, что еще это значит? Это значит, что теперь у нас только один строгий и самый важный судья — вы.
Мы не оглядываемся на других. Мы смотрим только на вас: на ваши результаты, ваши вопросы, ваши сложные кейсы. И в ответ мы становимся быстрее и смелее.
Заключение
«Госбаза» — это не кристальный шар. Это ваш высокотехнологичный металлоискатель с катушкой большего размера, встроенным GPS-модулем и искусственным интеллектом, который рисует тепловую карту поля, показывая, где концентрация «реликвий» выше.
Но последнее решение — нажать на курок или копнуть — всегда за вами. Ваша опытная рука, ваша чуйка и ваше умение интерпретировать сигналы — это то, что превращает груду данных в золотые монеты.
Помните три правила с поля:
-
Остановись и подумай (проанализируй прогноз с помощью «Фокуса внимания»).
-
Знай свой прибор (используй фильтры и понимай, как работает база).
-
Не сдавайся (если клиент «не идет», сделай 10 «контрольных» звонков по заведомо слабым прогнозам, чтобы убедиться, что инструмент в порядке, и иди дальше).
Однако даже лучший инструмент требует стратегии. Госбаза не гарантирует победу — она гарантирует преимущество. Она даёт вам не просто сигнал, а контекст:
-
историю побед компании,
-
её аномальную активность,
-
неявные связи с заказчиком,
-
тематические совпадения, невидимые глазу.
Это как услышать не просто «здесь есть металл», а «здесь монета XVIII века на глубине 30 см, а рядом — ржавый гвоздь». Вы экономите не время, а ресурсы внимания, концентрируясь только на перспективных целях.
И да — иногда алгоритм ошибается. Как и металлоискатель, который реагирует на пробку из-под пивной банки. Но именно ваше решение — проверить сигнал или отсечь его — финальный фильтр, который отделяет находки от мусора.
Ладно, признаю — я не Илон Маск, и мы не колонизируем Марс. Мы «всего лишь» предсказываем победителей госзакупок. Переходите на Госбазу — и пусть ваши конкуренты продолжают гадать, почему вы всегда оказываетесь первыми.
Удачи в поисках ваших золотых клиентов.